
There’s no denying that we live in a data-driven world. When your business comes across useful data that might be leveraged either now or at some point in the future, it’s necessary to securely store it in a centralized location — one that’s easily accessible to your entire organization.
Analyzing current and historical data provides invaluable insights into operations and leads to making better business decisions. This is precisely what data lakes and data warehouses can offer.
Data lakes and warehouses create a system which keeps data organized in one central location. This makes it easier for enterprise users to retrieve and work with the data as needed. But what’s the difference between the two, and which one is most suitable for your business?
In this brief data storage solutions tutorial, you’ll learn:
- The definitions and differences between data lakes, warehouses, marts, and hubs
- Architecture and implementation of both data lakes and warehouses
- Complementary products which can enhance or secure your data.
Data lake
What is a data lake?
A data lake is a system (or repository of data) stored in its raw format (object blobs or files). It’s usually a single store of all enterprise data. This enterprise data typically consists of raw copies of source system data, as well as transformed data that’s leveraged for various tasks. These tasks include carrying out functions such as reporting, visualization, analytics, and machine learning.
Data lake example sources:
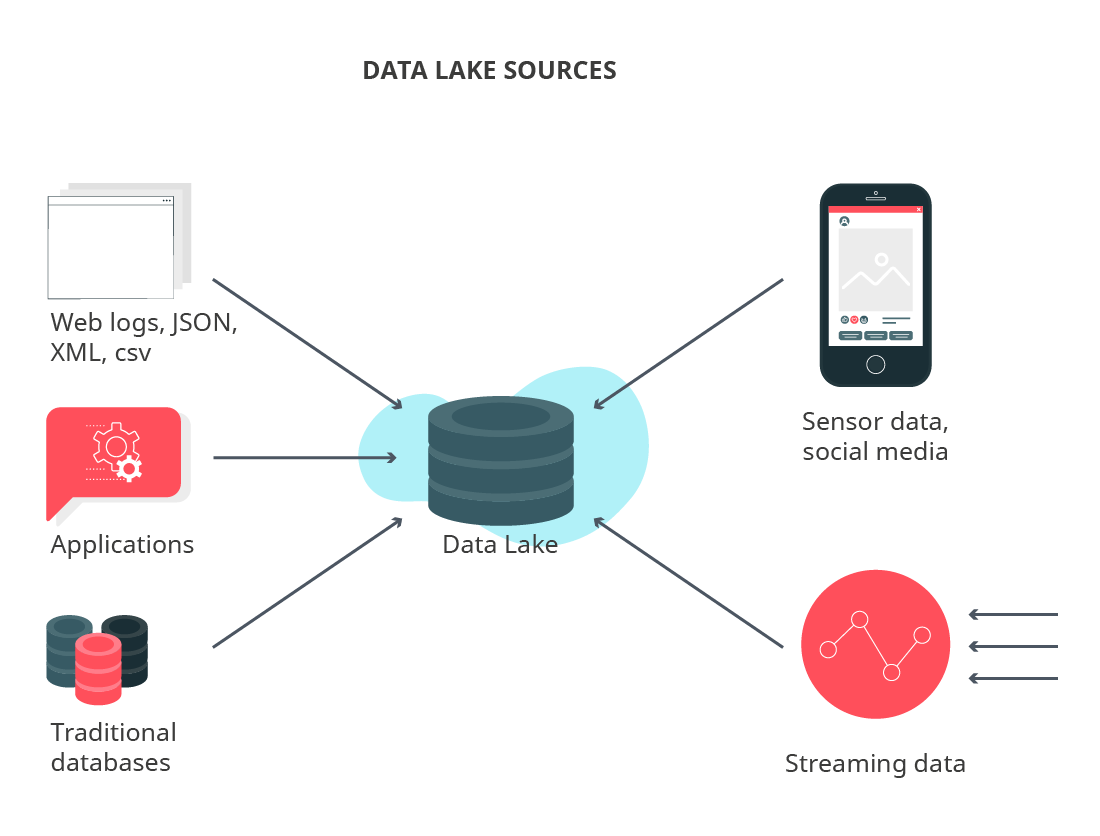
A data lake may include structured, semi-structured, unstructured, or binary data. It is typically (though not always) built using Hadoop. Data lakes can be established either on-premises or in the cloud.
If a data lake is unmanaged, deteriorated, or inaccessible, it becomes a “data swamp.”
Data lake storage benefits & challenges
Some of the obvious advantages of having a data lake include
- Possibility of deriving value from unlimited types of data
- Possibility of storing all types of data in a lake (from CRM data to social media posts)
- Possibility to work (analyze, gain insights) with raw data in the future
- Unlimited ways to query data
- Elimination of data silos
- Democratized data access while using an effective data management platform
While the advantages of data lakes are excellent, there are also disadvantages associated with creating and maintaining them. As Sean Martin, CTO of Cambridge Semantics argues: some enterprises create large data graveyards by dumping everything into Hadoop distributed file systems (HDFS), hoping they can do something with that data in the future. Yet, since most of it remains untouched for months or years, businesses tend to lose track of what they dumped.
Therefore, the main challenge is not creating a data lake, but rather managing it and taking advantage of the opportunities it presents.
Another disadvantage is due to the ambiguous nature of the data lake concept. This is because the data lake concept often refers to any tool or data management practice that doesn’t fit into traditional data warehouse architecture (more on that later). Furthermore, under the guise of data lake, different businesses imply different things (such as raw data reservoir, a hub for ETL offload, and others), which makes the viability of the definition questionable.
Data lake key attributes
A large data repository should possess three key attributes in order to be classified as a data lake:
- Data Collection – A single, shared repository of data that is typically stored within a DFS (distributed file system). Data lakes preserve data in its original form and capture data changes throughout the data lifecycle. This is extremely useful for both compliance and auditing purposes.
- Orchestration and Job Scheduling – Must provide workload execution, resource management, and a centralized platform. The centralized platform must deliver consistent operation, as well as security and data governance tools.
- Easy Accessibility – The ability to consume, process, or act upon the data. The data is preserved in its original form, then loaded and stored as-is. Data owners must be able to consolidate customer and operations data without any technical or political roadblocks.
Data Lake Architecture
According to an analogy made by James Dixon, the CTO of Pentaho, who also coined the term “data lake”: a data lake resembles a water reservoir where the flows originate from various sources and maintain their original format. On the other hand, a “data mart” (more on that later) is like bottled water, in the sense that it undergoes multiple filtering stages as data is processed.
Regarding data lake architecture, in its simplest form, it consists of three main layers:
- Sources
- Processing
- Target
Think of a data lake as a single repository that can be divided into separate layers, from which the following can be distinguished:
- Raw: Also referred to as the Ingestion Layer or Landing Area, the main objective of this layer is to ingest data as quickly and efficiently as possible, all while preserving its native format. Despite the allowance of “no overriding”, which means maintaining redundant and modified versions of the same data, raw data still needs to be organized into folders. End users are usually not allowed to use the data since it’s not ready.
- Standardized (optional): The main goal of this layer is to improve performance in data transfer from raw to curated. This includes daily transformations and demand loads. Rather than keeping the data in its native format, when using Standardized, the data is managed using whichever format is best suited for the cleansing operation.
- Cleansed: Commonly referred to as the Curated or Conformed Layer, it’s in this layer by which data is transformed into consumable data sets. These sets may be stored in tables or files. During this stage, denormalization and consolidation of data occurs frequently. Users are usually granted access to the data within this layer.
- Application: Often referred to as the Trusted, Secure, or Production Layer, it’s in this layer by which data is sourced from the Cleansed layer and enforced with any necessary business logic.
- Sandbox (optional): This layer specifically serves the needs of business analysts and data scientists, whom might experiment with data in their search for patterns and correlations.
Besides the aforementioned layers, there are other essential components which comprise data lake architecture. Among them are:
- Security: access control, encryption, authentication, etc.
- Governance: monitoring and logging operations to measure performance and adjusting the data lake accordingly
- Metadata: all the schemas, reload intervals, and descriptions of data
- Stewardship: assigning users with appropriate roles to govern the data
- Master data: an integral part of serving ready-to-use data
- Archive: maintain archive data that originates from a data warehouse (DWH)
- Offload: offload resources which consume ETL processes from your DWH to your data lake
- Orchestration and ETL processes: control the flow of data through the multiple architectural layers, from raw and cleansed, to the sandbox and application layers.
Data lake architecture can be illustrated with a scheme below:
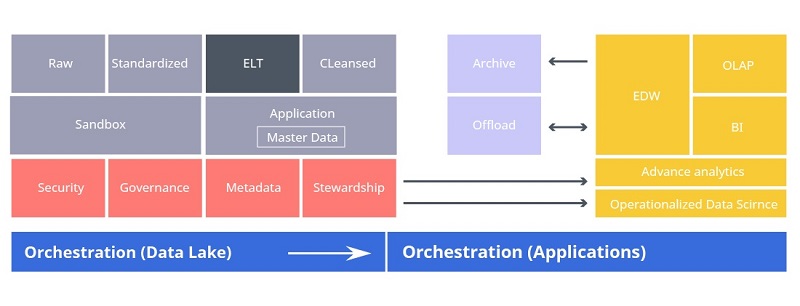
Within the scheme above, the data sources are represented with:
- Relation DB
- Streaming
- Social Media
- Web Scrapping
- No SQL DB
- Photos
- Word Documents
- PDF Documents
Data lake implementation
In order to successfully create a data lake, as with any project that aligns with the company’s business strategy and objectives, it’s necessary to have executive sponsorship and broad buyin. Additional prerequisites of a successful data lake formation include: the choice of the right platform, data, and interfaces.
Data lakes can be implemented using different data management tools, techniques, or services. Popular data lake implementation platforms include: Azure Data Lake, Amazon S3, IBM Cloud Pak for Data, or Apache Hadoop.
Apache Hadoop in particular has become the data lakes implementation platform of choice. It’s highly scalable, technology agnostic, cost-effective, and doesn’t have any schema limitations. While other open-source data lake solutions are available for architecting, designing, implementing, and consuming data lakes, Hadoop is the most commonly used.
When it comes to the choice of data, you’ll need to save as much data as possible in its native format. One of the challenges with acquiring the right data is data silos. Data silos occur when departments refrain from sharing data with each other. In data lakes, this challenge doesn’t exist, as the lake consumes raw data via frictionless ingestion.
When modeling a data lake, strong emphasis must be placed on the user interface. The user interface must be self-service and allow users to find, understand, and use data without assistance from an IT department.
There are two essential ingredients to enable self-service:
1. The data must be provisioned at the right level of expertise for users.
2. Users must be able to find the right data.
In order to satisfy the needs of diverse user populations (for instance, data scientists might need raw data, whereas data analysts want it harmonized), it will be necessary to construct multiple data lake zones. Data lake zones are areas which contain data that meets certain requirements. The best user interface resembles an Amazon.com paradigm, in which users “shop” for data and can also find, understand, rate, annotate, and consume it.
Data lake vs data hub
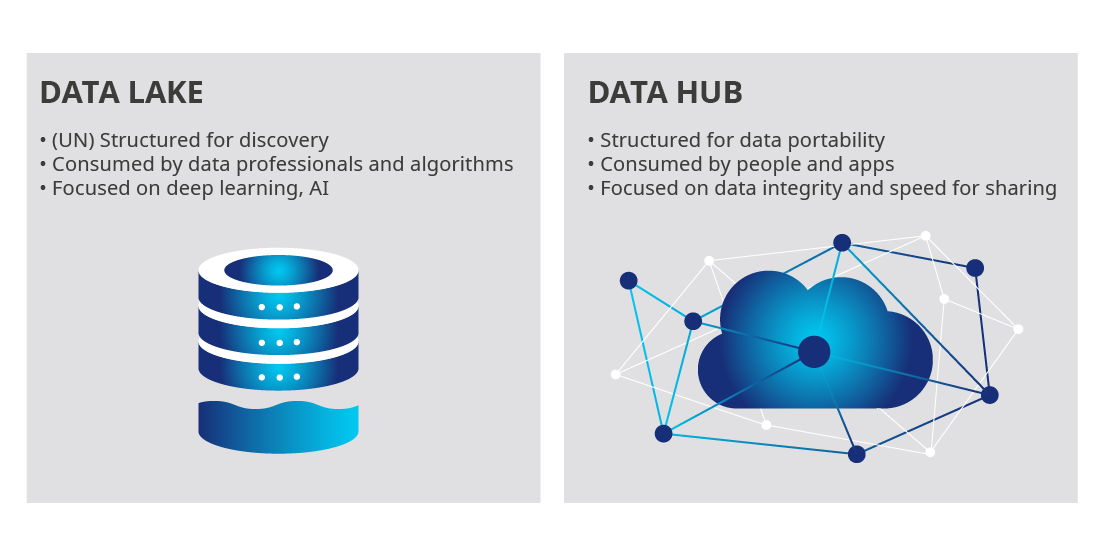
Data hubs (DH) are data stores that act as integration points in a hub-and-spoke architecture.
DHs centralize critical enterprise data across apps and enable seamless data sharing between diverse endpoints. At the same time, DHs remain the main source of trusted data for the data governance initiative.
DHs provide master data to apps and processes, but also serve as connecting points between business apps and analytics structures (which are data lakes and warehouses).
DHs are powered by a multi-model database, which data lakes do not have. This gives DHs the ability to serve as a system of truth with the required enterprise data lake security and provide features such as: data confidentiality, data availability, and data integrity.
Additionally, DHs support operational and transactional apps, which data lakes are not designed to handle.
These are the key differences between a data lake and a data hub:
| DATA HUB | DATA LAKE | |
|---|---|---|
| Primary usage | Operational processes | Analytics, reporting, and Machine Learning (ML) |
| Data shape | Structured | Structured and unstructured |
| Data quality | Very high quality | Medium and low quality |
| Data governance | The main source of all data administration and governance | Lightly governed |
| Integration with enterprise apps | Bi-directional real-time integration with existing business processes via APIs. | Mono-directional ETL or ELT in batch mode (dumping data in a lake for future cleansing) |
| Business user interactions | The source of authoring of key data elements (master and reference data). Has user-friendly interfaces for data authoring, data stewardship, and search. | Requires data cleansing/preparation before consumption. Used to stage ML data sets. |
| Enterprise operational processes | Primary repository (and conductor) for reliable data exposed in business processes. | Mainly ML processes. |
Data lake vs data mart
A data mart is a small repository of interesting attributes that’s derived from raw data. If you think of a data warehouse (which we’ll expand on further below) as a wardrobe with multiple shelves, then a data mart is just one of those shelves.
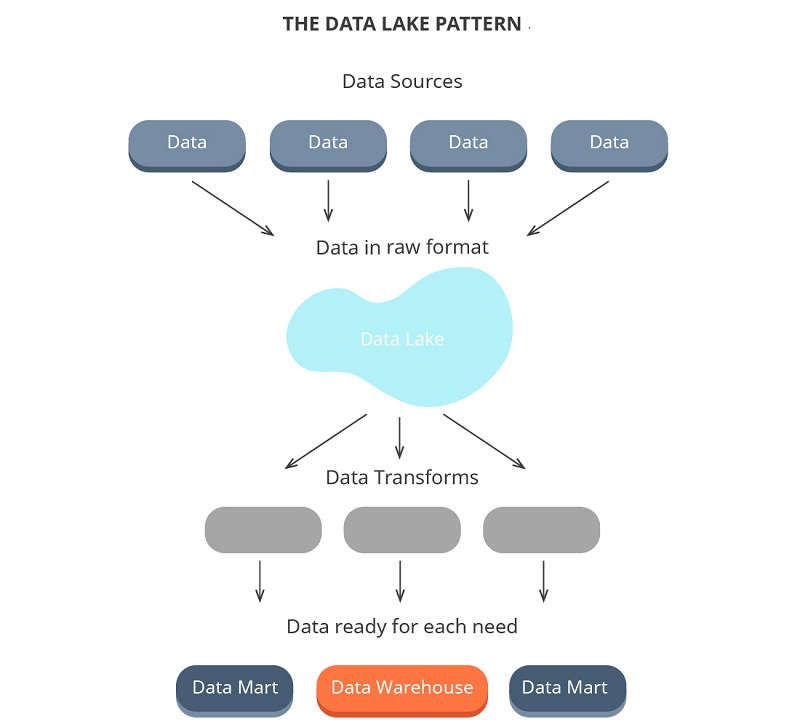
A data mart allows you to analyze a certain amount of data. Take for example, an accounting department. You could create a data mart for the accounts payable and only users from the accounting department would be able to see it.
A data mart provides subject-oriented data that benefits a specific set of people within the organization.
Data mart characteristics include the following:
- Focuses on one subject matter
- Deals with one business function
- Stores only one subset of data
- Uses star schema or similar structure
Data Warehouse
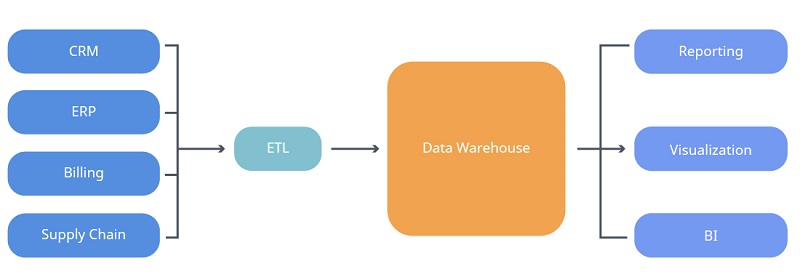
Data Warehouse Definition
A data warehouse (DW, DWH, or EDW) is a core component of business intelligence (BI). It’s also a system for reporting and data analysis. DWs are central repositories of integrated data from different sources, which store current and historical data in one single place. This data is then used to create analytical reports for various types of enterprise users.
The data that’s stored in the warehouse is uploaded from operational systems such as marketing, sales, or accounting. The data usually passes through an operational data store and requires some degree of cleansing. This is to ensure the data quality before it’s used for reporting.
Below are some of the most common data warehouse benefits:
- Enhanced business intelligence: by having access to information from various sources in a single platform
- Enhanced data quality and consistency: since DHW converts data from multiple sources into a consistent format
- Improved decision-making process: by providing better insights and maintaining a cohesive database of current and historical data
- Improved forecasting: by analyzing data, identifying potential KPIs, and gauging predicated results
Architecture
Data warehouse architecture consists of tiers:
- The top tier is the front-end client that presents results through reporting, analysis, and data mining tools.
- The middle tier is the analytics engine which accesses and analyzes data.
- The bottom tier is the database server, in which data is loaded and stored in two different ways. Frequently accessed data is stored on fast storage, while more seldomly accessed data is stored on a cheap object-store.
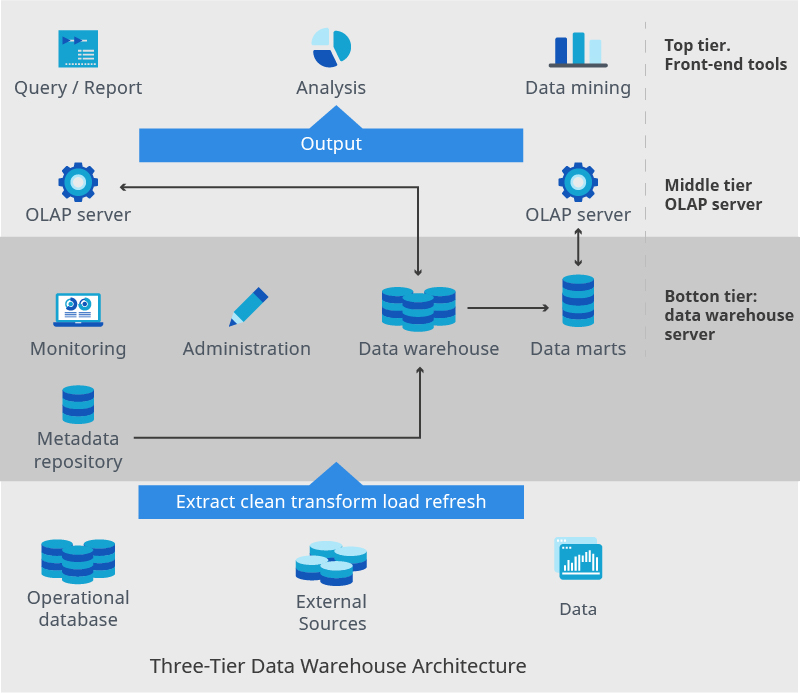
Let’s describe the above example infographics from the bottom up in more detail below.
As mentioned above, the bottom tier is the DWH server. This is typically an RDBMS (relational database management system), which may include several data marts or a metadata repository. Application program interfaces, which are used to extract data from operational databases and external sources, are referred to as a gateway. This gateway provides the underlying database and allows programs to execute SQL code on a server.
The middle-tier consists of an OLAP (Online Analytical Processing) server for fast querying of a data warehouse. An OLAP is implemented with either one of the following:
- A Relational OLAP (ROLAP) model – an extended relational database that maps functions on multidimensional data to standard relational operations
- A Multidimensional OLAP (MOLAP) model – a specialized server that directly implements multidimensional information and operations
The top-tier consists of front-end tooling which displays the results of OLAP, along with other tools for data mining OLAP generated data.
Data warehouse essential concepts
Enterprise data warehouses are central databases with organized, classified, and ready-to-use data. In EDW, data is usually labeled and categorized for easier access.
An operational data store (ODS) is specifically created for daily and routine activities. The database is updated in real-time and stores data for a chosen activity.
A data mart is a part of a data warehouse, which is designed to support a specific department, team, or function. Any information which passes through that department is automatically stored for later use.
The following are a few data warehouse models:
A basic data warehouse is a data warehouse structure whose objective is to reduce the total amount of data stored in the system. It accomplishes this by first centralizing information from a variety of sources, then removing any redundant information. In this model, employees access the warehouse directly.
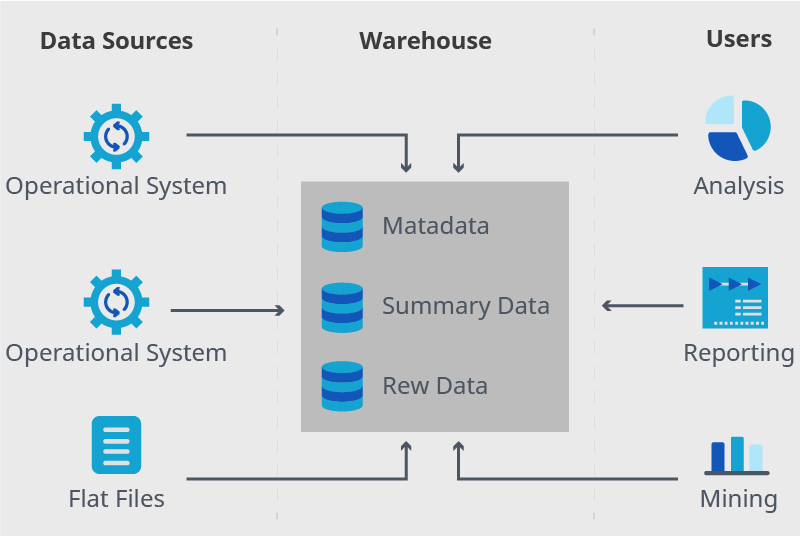
Data warehouses with a staging area are warehouses that clean and process data before it’s moved into storage. The “cleaning and processing” occurs within a staging area, in which the information is reviewed, evaluated, deleted, and transferred within the warehouse. A staging area ensures that only relevant information is stored within the software.
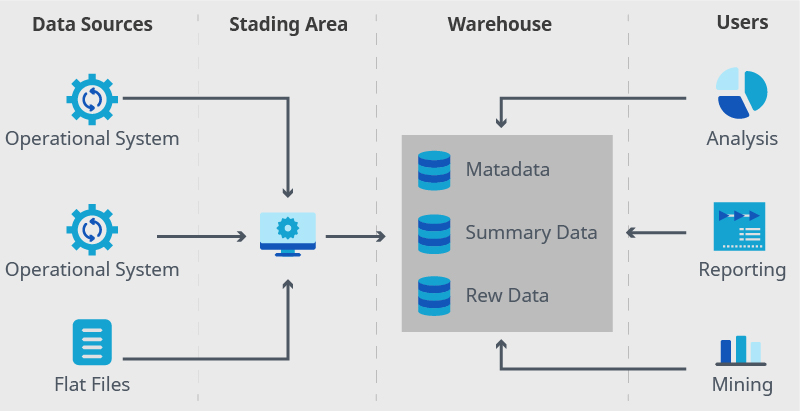
Data warehouse with data marts is where data marts complement the data warehouse by providing an additional level of customization. Once the data is processed and evaluated, data marts streamline information to relevant departments and teams.
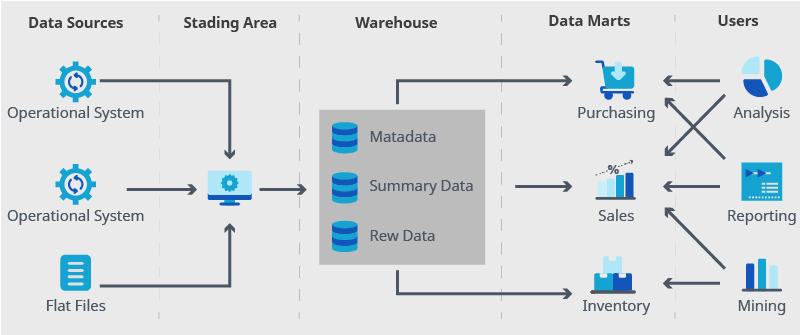
Related systems: Database, Datamart, OLAP & OLTP
Data is accessed and gathered in a database but analyzed and consumed in a data warehouse.
A database is a structured place to store data in a schema form. It is then used to manage the OLTP (Online Transactional Processing) operations with appropriate data security levels. In other words, in a database, all data can be gathered, stored, changed, and retrieved by anyone.
A data warehouse is an integrated and subject-oriented collection of data that has been retrieved from different databases. In a DWH, data is stored in a denormalized form to be used for OLAP (Online Analytical Processing), which is then used to aggregate queries and analytics.
Data warehouse vs database:
| CRITERION | DATABASE | DATA WAREHOUSE |
|---|---|---|
| Objective | to record | to analyze |
| Processing Method | Online Transactional Processing (OLTP) | Online Analytical Processing (OLAP) |
| Usage | fundamental business operations | business analysis |
| Orientation | application-oriented collection of data | subject-oriented collection of data |
| Storage limit | single application | any number of applications |
| Availability | real-time | refreshed from source systems upon request |
| Data Type | up to date | current and historical data (might not be up to date) |
| Tables and Joins | normalized | denormalized |
| Storage of data | flat relational approach | dimensional and normalized approach |
| Query Type | simple transaction queries | complex queries |
| Data Summary | detailed data | highly summarized data |
Since we’ve already covered data marts, for illustrative purposes, let’s briefly outline the major differences between DWH and data marts in the table below:
| ATTRIBUTE | DATA MART | DATA WAREHOUSE |
|---|---|---|
| Scope of data | department-wide | enterprise-wide |
| Subject areas | single | multiple |
| Difficulty of building | easy | difficult |
| Time to build | less | more |
| Amount of memory | limited | larger |
OLTP (Online Transaction Processing) contains several main characteristics, including: a large number of short online transactions (insert, update, and delete), a system emphasis on extremely fast query processing, and maintaining data integrity in multi-access environments. In OLTP, the system’s efficacy is measured by the number of transactions per second. The entity model (such as 3NF) is used as a schema to store transactional databases.
OLAP (Online Analytical Processing) processes a relatively low volume of transactions using complex queries and aggregations. One of the critical measures for OLAP is the response time, which is used to measure OLAP efficiency. OLAP databases store aggregated historical data in multi-dimensional schemas, such as star schemas. Three basic OLAP operations include roll-up (consolidation), drill-down, and slicing & dicing.
Let’s summarize the differences in the table below:
| CRITERION | OLTP | OLAP |
|---|---|---|
| Objective | online transactional system that manages database modification | online analysis and data retrieving process |
| Volume of data | large numbers of short online transactions | large volume of data |
| Functionality | online database modifying system | online database query management system |
| Method | traditional DBMS | data warehouse |
| Query | insert, update, and delete information | select operations |
| Table | normalized | denormalized |
| Source | sources of data are OLTP and its transactions | sources of data are different OLTP databases. |
| Response time | milliseconds | seconds to minutes |
| Data Integrity | integrity constraint | data integrity is not an issue. |
| Data quality | detailed and organized | might not be organized |
| Usefulness | controlling and running fundamental business tasks. | planning, problem-solving, and decision support. |
| Operation | read/write operations | read and rarely write |
| Audience | market-orientated | customer-orientated |
| Query Type | standardized and simple | complex queries involving aggregations |
| Back-up | complete backup + incremental backups | backup from time to time |
| Design | application-oriented | subject-oriented |
| User type | data-critical users | data-knowledge users |
| Purpose | real-time business operations | analysis of business measures by category and attributes |
| Performance metric | transaction throughput | query throughput |
| Number of users | thousands of users | hundreds of users |
| Productivity | increase user’s self-service and productivity | increase the productivity of business analysts. |
| Challenge | money | requires expertise |
| Style | fast response time, low data redundancy | integrates different data sources for building a consolidated database |
Data Warehouse implementation
There are two main approaches to build a data warehouse system:
- Extract, Transform, Load (ETL)
- Extract, Load, Transform (ELT)
ETL approach: Extract, Transform, Load
The typical ETL DW uses staging, data integration, and access layers to house its key functions:
- The staging layer stores data from each of the disparate source data systems.
- The data integration layer integrates the disparate data sets by transforming the data from the staging layer, then stores the transformed data in an operational data store (ODS).
The integrated data is then moved to yet another database, in which the data is arranged into hierarchical groups (or dimensions), facts, and aggregate facts. Facts and dimensions together are called a star schema.
- The access layer helps users retrieve data.
A broader definition of a DWH is a collection of business intelligence tools designed for the purpose of extracting, transforming, and loading data into a repository, as well as managing and retrieving metadata.
The following are several popular tools used to implement ETL-based DWH:
- IBM InfoSphere DataStage
- Informatica – PowerCenter
- Ab Initio Software.
ELT approach: Extract, Load, Transform
The difference between ETL and ELT-based DWH is that ELT DWH eliminates the need for a separate ETL tool to transform data. Instead, it maintains a staging area inside the DWH. This way, data is extracted from heterogeneous source systems and then loaded into the DWH before the transformation. The transformation is then later completed within the DWH. Lastly, the manipulated data is loaded into target tables in the same DWH.
The advent of powerful cloud solutions is changing big data analytics, especially as more companies shift their storage and workloads off premises. AWS (Amazon Web Services) has largely contributed to this phenomenon by kicking off the cloud data warehouse (CDW) wave with Redshift.
Let’s see which companies offer the best data warehouse cloud implementation solutions:
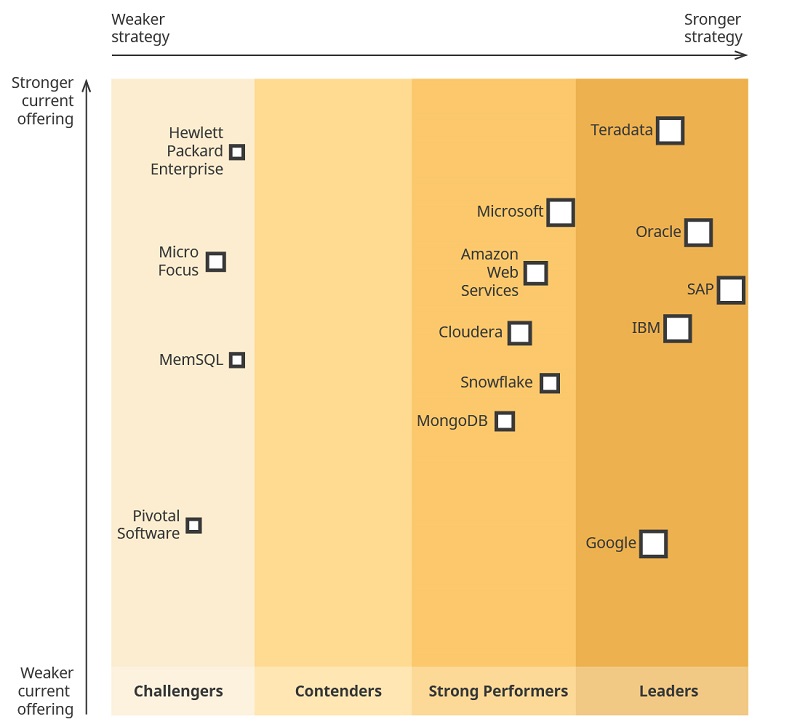
Data Warehouse Implementation guidelines
There are several rules to follow while implementing a data warehouse system in your organization.
Here are some examples of essential data warehouse rules:
- Build a DWH incrementally: create data marts for specific projects and once they are implemented, begin creating others. An EDW must be implemented in an iterative manner and allow data marts to extract all necessary information.
- Include quality data: only high-quality data implicit to the organization(s) should be loaded onto the DWH.
- Align with corporate strategy and create a business plan: a DWH project should align with business goals and the broader enterprise strategy. This includes, but is not limited to: the project’s purpose, costs, and advantages. The importance of constructing a solid, clearly documented plan cannot be overstated.
- Train staff: for any projects to be successful, users must be trained first. This is to ensure their understanding of DWH capabilities.
- Create for adaptability: built-in flexibility allows making changes if and when required.
- Involve all specialists: both IT and business professionals must work together to ensure that the project aligns with business objectives.
Data Warehouse Implementation for data mining
First, let’s define data mining with regards to data warehousing. While a data warehouse involves compiling and organizing data, data mining is the process by which useful data is extracted from those databases. Data mining then leverages the data compiled within the data warehouse to recognize meaningful patterns. Data mining projects do not require a data warehouse infrastructure. However, large organizations will benefit from data mining the existing data stored in the data warehouse.
Let’s dive into the data mining concept a little further, and then we’ll discuss the process of using data warehousing for data mining.
The important features of the data mining process include:
- Automatic discovery of patterns
- Prediction of the expected results
- Focuses on large data sets and databases
- Creation of actionable information
Data mining techniques include:
- Transforming raw data sources into a consistent schema for analysis
- Identifying patterns in a dataset
- Creating visualizations which translate the most critical insights
Data mining tools utilize AI, statistics, machine learning, and other technologies to establish the relationship between the data.
This is how data mining fits within the data warehouse concept:
- First, the relevant data is loaded into the warehouse.
- Data engineers then select relevant data sets and remove irrelevant data.
- The data is pre-processed and cleaned to remove noise and improve the quality of data.
- Data engineers transform the data into a format suitable for machine learning analysis.
- During data mining, the data is run through one or more machine learning or NLP models for the purpose of extracting relevant data.
- Data miners examine the results and fine-tune models to determine their validity and relevance.
- Lastly, data miners prepare reports which explain the insights and their values.
Data that’s properly warehoused is easier to mine because if a data mining query must navigate through multiple databases, which might be scattered across different physical networks, it won’t be efficient; and thus, getting the results may take longer.
Therefore, the task of a data warehouse expert should be attempting to closely connect relevant data in different databases within a data storage system. The end goal is to ensure that the data miner executes much more meaningful and efficient queries. From the seven steps outlined above, you can see that data has to travel through a long pipeline before it’s ready to be mined.
Traditionally, processing and cleaning of data were manual tasks. However, thanks to the availability of automated technologies, the process has become less laborious. The automated data warehouses leverage machine learning and NLP technology to ingest raw data and automatically prepare it for any type of analysis.
This process makes data mining relatively effortless. Using this level of automation, data miners can select data sources, ingest vast amounts of raw data, and enable data mining analysis through a point-and-click interface in a matter of minutes.
Data Warehouse Implementation in healthcare
The healthcare industry produces massive amounts of data. Due to the rise of electronic health records (EHR), digital medical imagery, and wearables, the healthcare industry’s data consumption is accelerated.
Building analytic dashboards and machine learning models on top of the available data sets can help healthcare providers improve treatment outcomes and their patients’ overall experience.
For medical research, scholars consistently utilize various organizational approaches, including: classification, clusters, decision trees, and more. This often results in double work, as similar efforts others have contributed to their own projects become redundant. Moreover, none of the existing challenges are mitigated.
Thus, organizing data and creating a data warehouse are extremely important for both commercial and academic activities within the healthcare industry.
The data warehouse solutions in healthcare should be able to support decision-making activities and create an infrastructure for ad hoc explorations of large data collections. Users should be able to complete their investigations without aid from an IT department by leveraging browsing tools. Therefore, while creating a DWH, a strong emphasis must be placed on ease of access and a user-friendly, intuitive interface. The star schema has been recognized as one of the most effective structures for organizing the healthcare data warehouse system.
The Data Warehouse design includes three levels of data granularity, ranging from coarse-grained data (generic report production) to detailed event-level data (hospital discharges).
- At the top level resides tables with highly aggregated data. These tables provide fast, interactive response times for access via data browsing tools.
- The middle level is supported by star schemas, which provide true dimensional data warehouse capabilities (interactive roll-up and drill-down operations). These schemas require more sophisticated data browsing tools to support OLAP techniques.
- The bottom level retains fine-grained or event-level data. This data is retained at the individual transaction level.
While gathering the sources for a data warehouse system, engineers use the CATCH method. CATCH translates the healthcare data into common formats and integrates it with other DW components for healthcare reports. Primary data sources include data gathered from door-to-door/mail-in surveys. Secondary data sources include healthcare data from hospitals, local, state, and federal health agencies, as well as national healthcare groups.
Each of those CATCH indicators is organized into categories with many accompanying indicators, which together represent a wide spectrum of healthcare issues. In many data warehousing projects, data staging accounts for most of the project workload.
This is because it composes a wide range of activities which focus on extracting data from operational data sources, transforming (or preprocessing) the data, and loading it into the warehouse. Twin-star data staging is commonly used for this process.
Data Warehouse Implementation for business intelligence
Though business intelligence (BI) and data warehousing (DW) are two different concepts, their synergy is where businesses derive the most value. Because of the inherent interconnectedness between the two, some have conflated the two concepts into one — BIDW (Business Intelligence/Data Warehouse). So why do the two terms come together? Are they interrelated? Let’s dive into it.
Business intelligence is the application of various tools for transforming data into actionable insights. In fact, that’s an umbrella term for all the apps, infrastructure, and best practices that have or enable access to the analysis of information to drive better business decisions.
BI includes
- Reporting processes (aggregating data on organizational performance);
- Visualization (static or interactive charts to make raw data more comprehensive);
- Sophisticated analyses (with AI and machine learning).
In short, BI is a generalized term for the process where the company initiates various activities to gather market information (including that of the company’s competitors). Thus, data warehousing is the infrastructural component for achieving BI.
In what follows, we’ll look more closely at data warehousing vs data lake and what’s best for your business.
Data Warehouse vs Data Lake
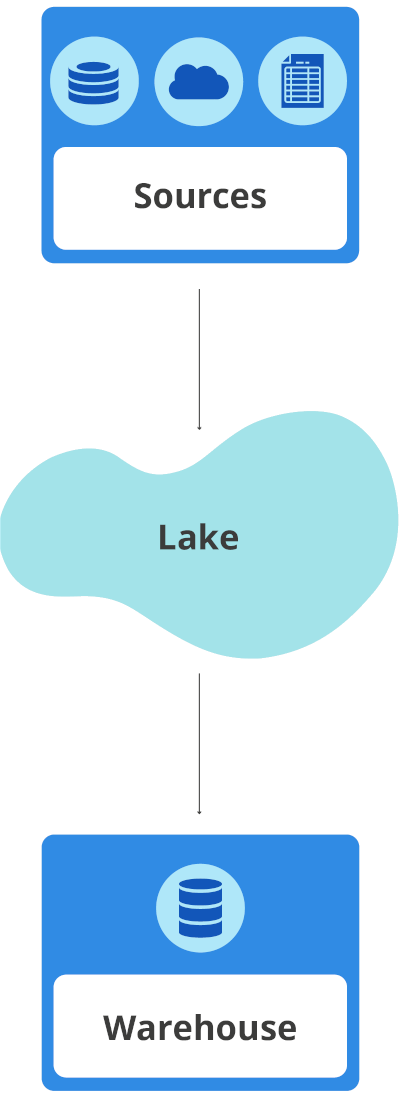
From the above, we can identify at least three key differences between data lakes and warehouses:
- Data structure
In a data warehouse, everything is neatly stored and organized in a specific order. Prior to being accepted in the DWH, the data is processed and converted into a specific format. Also, the data originates from only a select few sources and powers only a specified set of apps.
A data lake on the other hand is massive and far less structured. It’s a flexible repository of both structured and unstructured data that is stored because of its potential to become valuable in the future. The data lake approach is financially advantageous because data lakes don’t require preliminary cleansing or processing, don’t require a schema prior to ingesting the data, and can hold a larger and wider quantity of data.
- Objective
In a data warehouse, the costs of data cleaning and processing are expensive. Therefore, the costs should be offset with minimal storage costs. Due to this, the storage space becomes limited, forcing engineers to store only the data whose purpose is well-defined.
However, the purpose of the data in a lake is undetermined; as is why and where it’s going to be used.
- Accessibility
Data lakes are more accessible because the data is stored in a raw format. This makes it easier to access and change data as necessary.
Data warehouses on the other hand take time to transform data into a different format.
What’s better for your business: data lakes or data warehouses?
The two options are not mutually exclusive or conflicting, and ultimately, they should work together to complement one another.
The neatly organized storage in a data warehouse makes it easy to get answers to predictable business questions. For example, if your company’s stakeholders ask for the same type of data every month, then it doesn’t make sense to store any other data. But if businesses want to explore the data and its possibilities, then data lakes come into play.
In data lakes, a schema is applied to data when it’s loaded into the lake. More specifically, the schema is applied when data is about to be used for a particular purpose. The purpose essentially dictates which schema will be used. The flexibility that comes with data lakes allows data scientists to experiment with the data and determine how it can be leveraged. The metadata created and stored along the raw data allows for trying different schemas, structured formats, and more.
Data lakes can benefit and augment the power of a data warehouse in many ways, such as:
- Explore the potential of data beyond the structured capabilities of a data warehouse
- Use data lakes as a preparatory environment to process data before it’s fed to the data warehouse
- Work with streaming data since data lakes are not limited to batch-based periodic updates
While a data warehouse is certainly a key component to the enterprise data infrastructure, a data lake is crucial for research, analysis, and storage of data which might be of use later.
Complementary solutions to DL/DW
It’s a no brainer that these massive amounts of data must be properly maintained. If a data warehouse or data lake is not deployed in the cloud, and there is no paired ESX, then you may need HDM backup solutions for backup and recovery. You can also build an application for data backup using Paragon’s PCB SDK.
If DL\DW is deployed in the cloud using either vSphere or Hyper-V virtual environments (the two most widely used virtual environments), then there’s no particular need for a backup. In a cloud system, data safety and integrity are a given, as you can easily restore data from history. However, sometimes a data migration is required.
For example, if you need to migrate between the above virtual environments, then you might do so with Paragon’s HDM. You can also implement a similar functionality through Paragon’s open PCB SDK, where you can develop a migration strategy to any environment you want (for more details you can contact Paragon directly).
If you have found a spelling error, please, notify us by selecting that text and pressing Ctrl+Enter.

Leave a Comment